
Posts
How I Built a Custom Tool to Automate a Comic Book Publisher’s Ebook Creation – and Save Them Hundreds of Thousands of Dollars
We worked together to build a solution that they could start using quickly and dramatically cut down their conversion costs and time
I recently had the great pleasure of helping a comics publisher automate their PDF-to-ebook conversion process. As both a big comics nerd and someone who loves a new automation challenge, this was a perfect fusion of my professional expertise and personal interests. The project started when the publisher’s technical expert reached out to me with an idea: they were currently spending a couple hundred bucks per book to convert from PDF to fixed-layout EPUB (the standard file format for comics ebooks) – a process that took one or two weeks at minimum. Could I help them automate that process, providing a massive reduction in costs and turnaround time?
Yes indeed!
Step 1: Establish Requirements
The first and most basic step was to establish the formal goal with the publisher’s team. I met with both their technical experts as well as their production team to go over the current process, talk through some options, and nail down the final deliverable:
-
A bundle of scripts (with a user interface, eventually) that can be run by the publisher’s technical team
-
Accepts one or many print-ready PDFs as input
-
Also accepts an accompanying metadata .xls (Microsoft Excel) file as input
-
Outputs a fixed-layout EPUB of each book
-
Outputs a Web-friendly PDF of each book (cropped PDF that includes bookmarks and the cover)
-
Also accepts a front cover file for each book, and inserts it into the output files
-
Also accepts an optional new copyright page to be added to any specific book
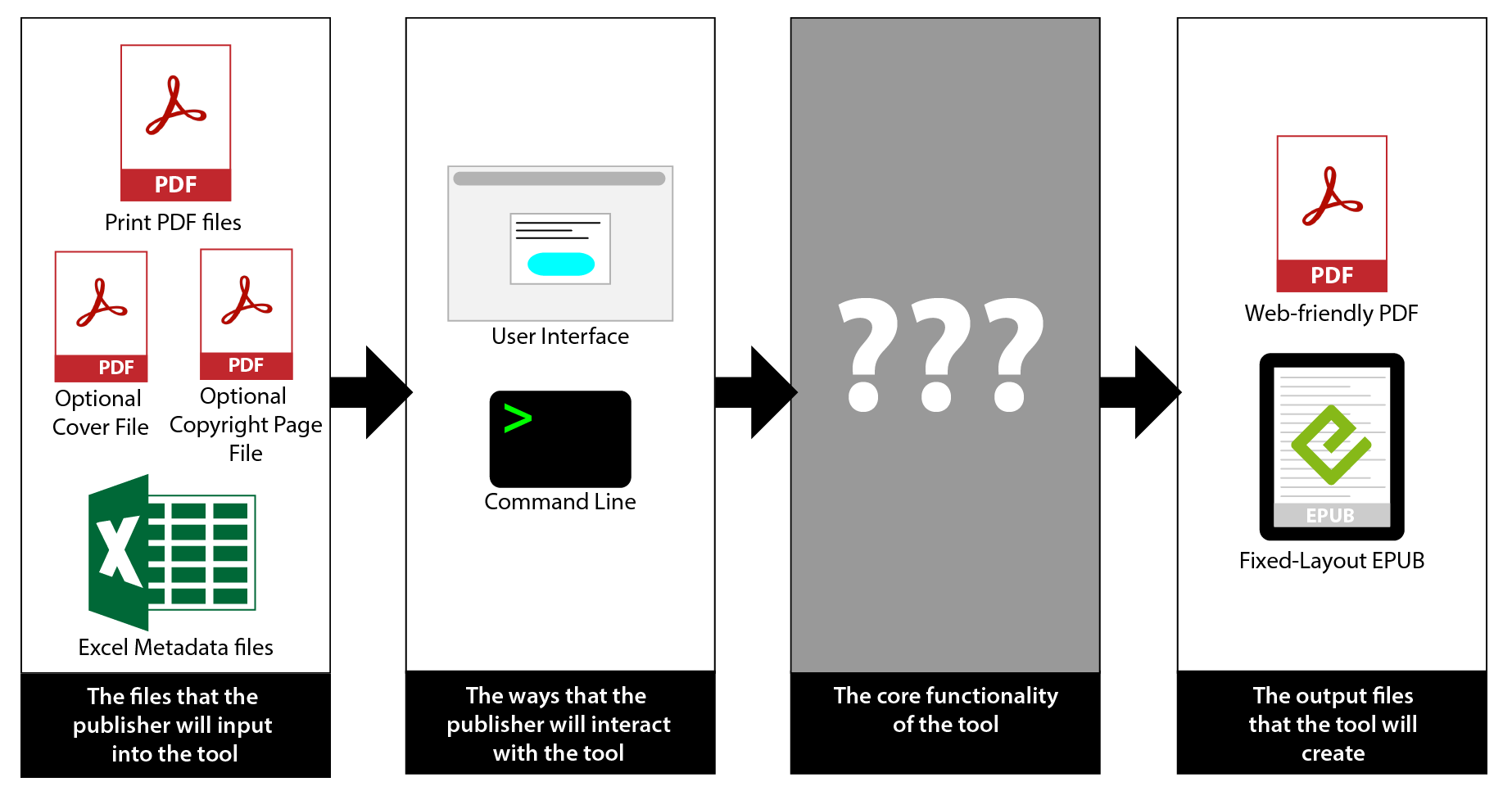
Step 2: Develop the Technical Approach
Once we had the requirements nailed down, I did a focussed round of file analysis. The publisher sent me samples of some of their past ebook files (created by a conversion vendor), the accompanying print PDF for each book, as well as the original InDesign files used to create that print PDF. I opened up the EPUB files and took a look at the code, with some specific questions in mind: What kind of syntax were they using in the HTML?, What metadata tags were they using?, How was the spine set up (the part of an EPUB file that dictates the flow of the book)?, etc. This created our baseline for the output from the new scripts – the minimum level of quality that we needed to meet (because the files from the scripts needed to be at least as good as the files they were getting from vendors).
Based on the file analysis and deliverable requirements, I put together a technical approach. I needed to take into account 2 important variables:
-
At least for a while, employees of the publisher would be running this code using the command line on their own computers; they have varying levels of technical expertise and could be running different operating systems with different capabilities (memory, hard drive space, etc.)
-
Eventually, a frontend/user interface will be interacting with the core script functionality as well – how can we save ourselves some work when we get to that point?
Taking those things into account, I decided to bundle all the core conversion functionality into a “serverless” function. This is a regular script that is hosted in a serverless environment somewhere on the Web (e.g., using AWS or Google’s infrastructure) – it’s a standard way of building light-weight applications that can be reused in a variety of places. By doing this, I was able to avoid having to install a lot of code libraries onto the publishing employees’ individual machines, and we can reuse this serverless function in the future user interface as well.
I would then create a much more basic script that simply needed to take the user’s input files and send them over to that serverless function. This script requires very little setup, so it’s easy to get different people up and running regardless of the type of operating system or machine they use, while all the powerful computing processes are running in the serverless function on the Web.
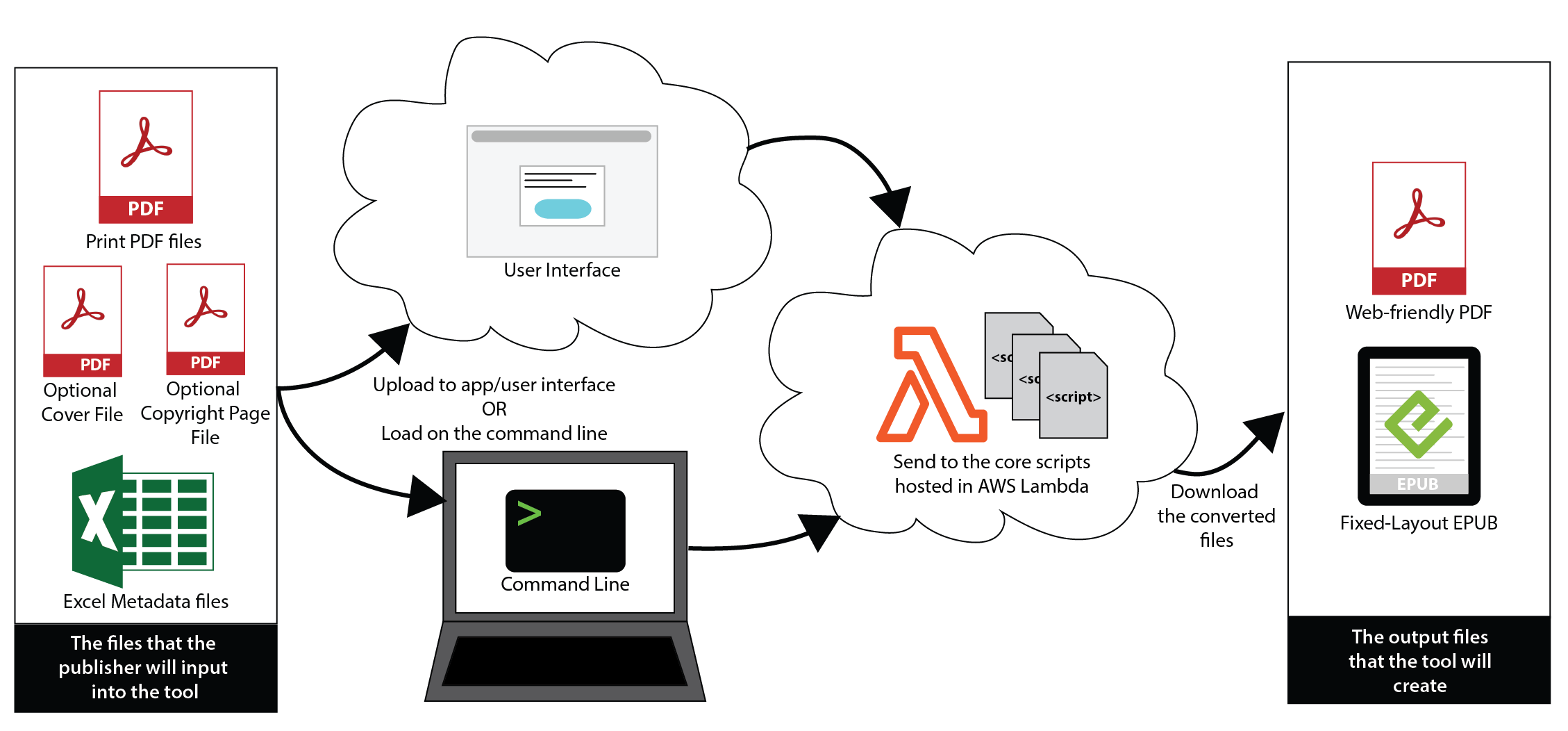
Step 3: Do the Work (in Phases)
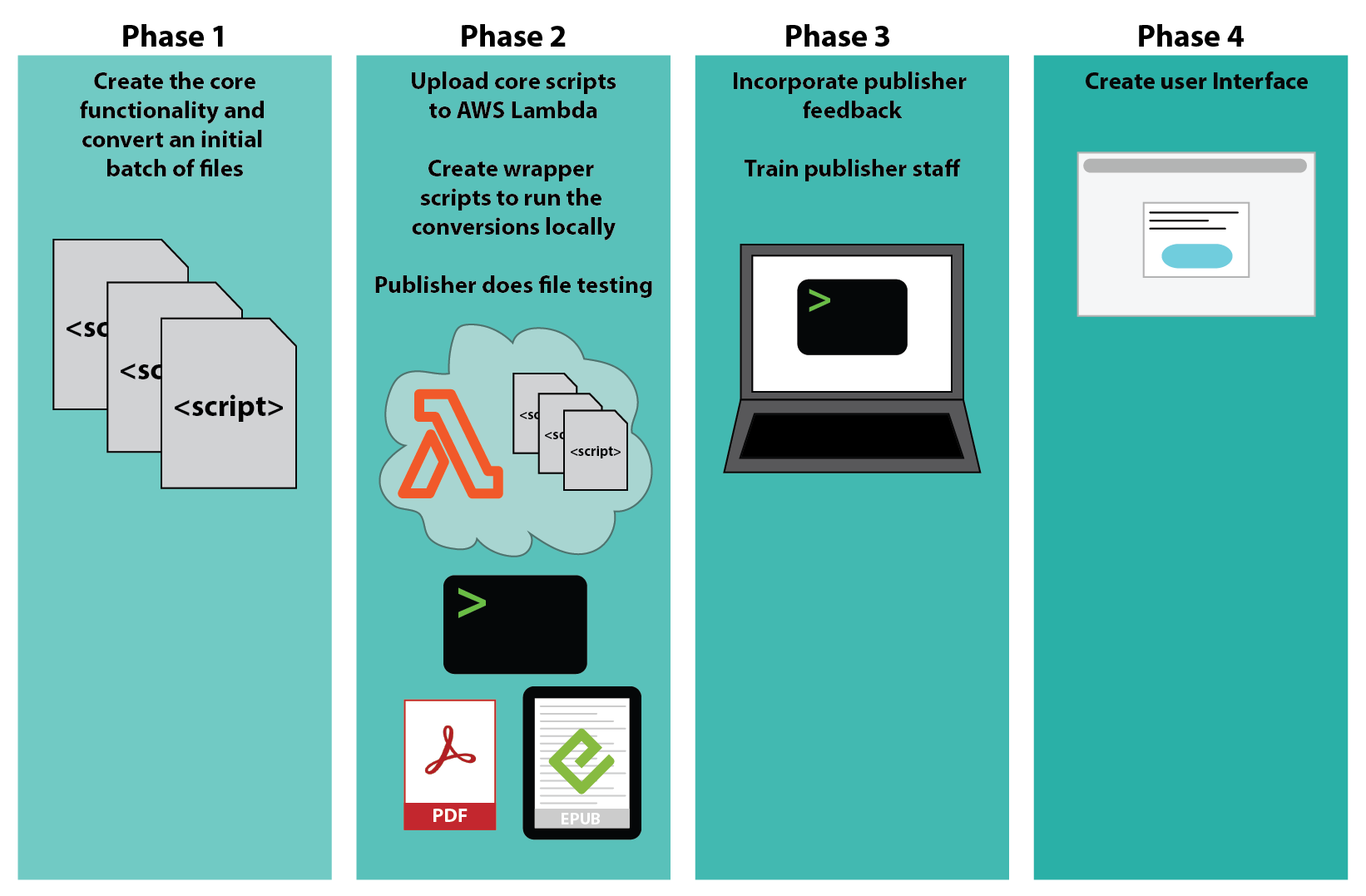
Now that I had my technical approach, I put together the full project plan. I wanted to help the company start using the automated process as quickly as possible, so I chunked the work into phases:
-
Phase 1: Get the core functionality working to convert EPUB and Web PDF files.
-
Phase 2: Create the wrapper scripts that the publisher’s team can run, and upload the core functionality to the serverless function; simultaneously, the publisher’s team will review and test the initial batch of converted files created during phase 1.
-
Phase 3: With the feedback from phase 2, generate polished files and functionality, ending with final script handoff and training.
-
Phase 4: Build a user interface (future deliverable), so that the publisher’s team doesn’t need to use the command line. Building the backend functionality first and getting their technical team to use it gives us a chance to debug and build handling for edge cases before we build the frontend. This saves time and money, since by the time we build the frontend, we’ll have the backend (aka our “bundle of scripts”) working solidly and will know exactly what features need to be supported.
The first phase was to just get some output from the tool that matched our goal output. I built the core functionality and ran it locally (on my own computer) using the samples provided to me by the publisher. I then handed the output EPUB and Web PDF files over to the publisher so that they could review and provide feedback.
Next, I deployed the core functionality to the serverless function while the publisher’s team reviewed the output samples to identify any issues or errors. I also created the simpler scripts that the publisher’s team would be running to interact with the serverless function.
Finally, I fixed any issues reported by the company and got everything polished and ready for handoff. To wrap up phase 3, I met with the publisher’s team and walked them through getting the scripts set up on their computers and converting files.
Of course there were issues that popped up during the process, and new questions to be answered or functionality that we missed during the initial planning (that’s pretty normal for these kinds of projects). I worked closely with the publisher’s team to tackle each thing as it came up, and find solutions that fit into the new streamlined process without bloating the project plan. We also established a long-term maintenance plan, so that the publisher’s team could come to me with questions, any inevitable bug fixes, and support for “edge cases” (special situations that don’t affect every book and are harder to plan for).
Final Thoughts
While the automated scripts already present a major savings in terms of time (conversion now takes anywhere from 30 seconds to 5 minutes, depending on the book, rather than the 1-2 weeks it previously took) and money (instead of paying a couple hundred dollars a book, they’re now only paying minimal server costs to host the script functionality), the “bundle of scripts” approach creates a slight bottleneck for the publisher’s team, since regardless of how simple the scripts are, they still require some technical ability and comfort with the command line. The next phase – bundling the functionality into an app by adding a frontend/user interface – will allow more members of the team to convert books without requiring any technical expertise or individual computer setup. Just log in, upload a PDF, and get a fixed-layout EPUB!
